本入门指南适用于对稳定扩散或其他人工智能图像生成器毫无经验的新手。
您将了解 Stable Diffusion 的概述以及一些基本使用技巧。
本文是《入门教程》系列的第一篇。
第二篇:提示词构建。
第三篇:图像修补(Inpainting)。
第四篇:模型(Models)。
Stable Diffusion AI
Stable Diffusion AI是一种稳定的AI扩散模型,可以生成美观的图片。这些图片具有照片级的写实感,或者像艺术家的绘画作品。
最关键的是:它完全免费并且速度非常快——你甚至可以在自己的个人电脑上跑起来。
那如何开始使用 Stable Diffusion?你需要一个描述图像的提示词(Prompt)。例如:
gingerbread house, diorama, in focus, white background, toast , crunch cereal
对应中文为:
姜饼屋、场景模型、对焦、白色背景、烤面包、脆脆玉米片。
然后就会生成下面的图片:



市面上已经有了 DALLE 和 MidJourney 这些优秀的文生图服务。为什么要用 Stable Diffusion呢?因为 Stable Diffusion 有3个优势:
- 开源且免费:许多热心的爱好者创建了这个免费的、强大的工具。
- 为低功耗计算机设计:运行成本低,免费或价格便宜。不需要高级的显卡就能跑起来。
- 没有审计:你不用担心违反了平台内部的规则。
Stable Diffusion 在线体验
理解 Stable Diffusion 最好的方式是实际体验。
下面是一个精简版的在线体验工具,可以让你不用下载软件就能在线体验 Stable Diffusion 的乐趣。只需要四个简单的步骤:
- 闭上你的眼睛。
- 想象一个你想制作的图像。
- 用尽可能详细的描述性词语描述图像。(为了获得最佳效果,请确保包含主题和背景,并使用很多描述性词汇)。
- 将其写入下面的提示(Prompt)输入框中。
负面提示词(Negative Prompt)可以不用修改,因为这种提示词一般来说是通用且固定的。
以下是可供尝试的几个提示词:
a cute Siberian cat running on a beach
一只可爱的西伯利亚猫在海滩上奔跑。
a cyborg in style of van Gogh
一位仿梵高风格的赛博格人。
french-bulldog warrior on a field, digital art, attractive, beautiful, intricate details, detailed face, hyper-detailed closed eyes,zorro eye mask, artstation, ambient light
一只法国斗牛犬勇士正在田野上战斗,数码艺术,吸引人,美丽,复杂的细节,详细的面孔,超详细的闭眼,佐罗眼罩,ArtStation,环境光线。
下面是其中一个效果:
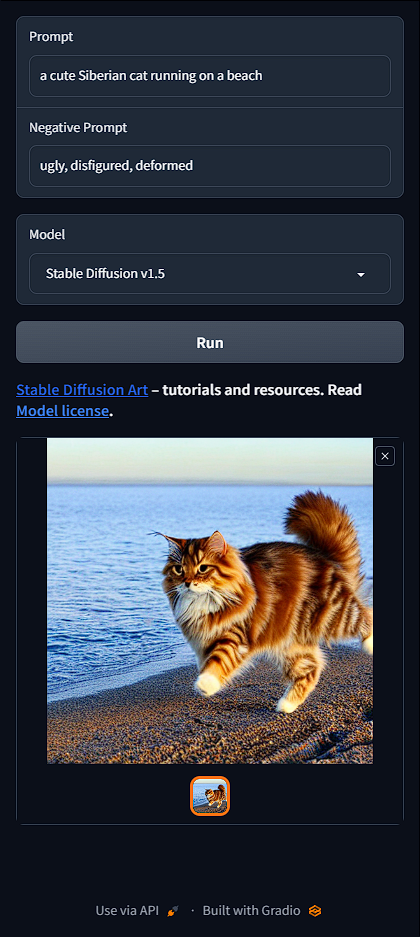
切换模型(Model)以查看不同的效果。你将在本指南的最后一部分学习有关模型的知识。
Stable Diffusion v1.5:正式的基本模型。在所有样式中都非常通用。
Realistic Vision v2.0:擅长生成像照片般逼真的图像。
Anything v3.0:动漫风格。
你可能注意到图片的质量时好时坏。不用担心,有许多方法可以改善图片。请继续阅读。
使用 Stable Diffusion 可以生成哪些图片呢?
这完全取决于你的想象力!下面是一些例子。
动漫风格 | Anime style



照片般真实 | Photo-realistic


Learn how to generate realistic people like these.
风景 | Landscape



奇幻 | Fantasy



艺术风格 | Artistic styles



动物 | Animals



Learn how to generate animals.
如何正式开始?
在线生成器
对于完全初学者,我建议使用上面的免费在线生成器或其他在线服务。这样你就可以开始生成而无需费心设置。
高级图形界面(Web UI)
免费在线生成器的缺点是功能非常有限。如果您需要更高级的图形用户界面,可以选择更为强大和广受欢迎的AUTOMATIC1111。
您有2种方式可以使用:
- 通过Google Colab云服务器来使用。
- 通过国内的 AutoDL 租用 GPU 进行使用。
如果您的PC具备合适的 NVIDIA 显卡,并至少具备 4 GB 的显卡内存,则在电脑上运行也是一个不错的选择。
使用高级图形界面的好处在于您可以使用整套工具来处理您的任务。
- 提示词自动补全、自动联想。
- 使用 Inpainting 重新生成图片的某一部分。
- 图生图(img2img):使用一张图片,生成另一张类似的图片
- pix2pix:使用提示词来修改图片。
- 反推:根据图片反推提示词。
如何构建一个好的提示词?
制作一个好的提示词需要学习很多,但基本点是尽可能详细地描述你的主题,并使用强有力的关键词来定义其风格。
建议先从使用 提示词生成器 开始。对于初学者来说,学习一组强大的关键词并掌握其效果是至关重要的,这就像学习一门新语言的词汇。你也可以从 [这里] 找到一些常用的提示词和用法。
生成高质量图像的一个快捷方式是复用现有的提示。找到一些提示词收集网站,比如 https://prompthero.com/,选择一张你喜欢的图像,然后直接复用它的提示词!不过这样做的缺点是你可能不理解它为什么能生成高质量的图像。阅读说明并改变提示以查看效果。
或者,使用像Playground AI这样的图片收集网站。选择一张你喜欢的图片并重新设计提示。但是,对于高质量的提示,这有点像大海捞针。
把提示词视为一个起点,根据需要进行修改。
好的提示词规则
有两个规则:
(1)要详细具体,
(2)要使用有力的关键词。
要详细具体
尽管人工智能的进步突飞猛进,但稳定扩散仍然无法读懂你的思维。因此,你需要尽可能详细地描述你的图像。
比如说你想生成一张街拍美女照片。一个简单的提示语:
a woman on street
一个在街上的女人
会给你生成一张像这样的照片:

显然你并不想要一个老太太,但你的提示词中也没有说不要老太太,所以程序会随机给你生成一个女人。
要想生成你要的图片,必须更加详细:
a young lady, brown eyes, highlights in hair, smile, wearing stylish business casual attire, sitting outside, quiet city street, rim lighting
一位年轻的女士,棕色的眼睛,发丝上有亮点,微笑着,穿着时尚的商务休闲服装,坐在安静的城市街道上的户外区域,周围透着微弱的光线。

强有力的关键词
有些关键词比其他关键词更有力量。例如:
- 名人(例如艾玛·沃森)
- 艺术家(例如梵高)
- 艺术媒介(例如插图、绘画、摄影)
谨慎地使用它们可以引导图片朝你想要的方向发展。
那些参数是什么,是否应该进行更改?
大多数在线生成器允许您更改一组有限的参数。以下是一些重要的参数:
- 图像大小(Image size):输出图像的大小。标准大小为512×512像素。将其更改为纵向或横向大小可能会对图像产生重大影响。例如,使用纵向大小生成全身图像。
- 采样步骤(Sampling steps):至少使用20步。如果看到模糊图像,则增加步骤。
- CFG比例(CFG scale):典型值为7。如果要更好地遵循提示词生成图像,则增加比例。
- 种子值(Seed value):-1会生成随机图像。如果要生成相同的图像,则需要指定一个值。
我需要生成多少张图片?
在测试一个提示语时,你应该总是生成多张图片。
当我对提示词做出大的修改时,我会一次生成2-4张图片,方便我进行快速验证。当我做小的修改时,我会一次生成4张图片,以增加看到有效画面的机会。
有些提示词只有不到50%的出现概率。因此,不要只根据一张图片就否定一个提示语。
什么是图生图(image-to-image)?

图生图(简称img2img)需要输入两个参数:图片和提示词。通过输入的提示词,你可以对图片的生成过程进行指导。
实际上,文本转图像(txt2img)可以看作是图生图(img2img)的一个特例:只不过它的输入图像是随机噪声图像。
不过,img2img技术是一种被低估的技术。你可以利用它轻松画出专业级的图画和卡通风格的图片。
修复图像缺陷的常用方式
当你在社交媒体上看到那些令人惊叹的AI图像时,很可能它们经过了一系列的后期处理。在本节中,我们将讨论其中一些常用方式。
人脸修复

众所周知 AI 不擅长生成面部图像。经常会出现一些瑕疵。
我们通常使用专门用于修复面部图像的图像AI模型,例如AUTOMATIC1111 GUI内置支持的CodeFormer。
对于版本v1.4和v1.5,更新了模型之后,可以修复眼睛的问题。
使用 inpainting 修复小的瑕疵
在第一次尝试中很难得到你想要的图像。更好的方法是制作一张具有良好构图的图像,然后使用 inpainting 修复缺陷。
以下是 inpainting 修复前后的图像示例。使用原始提示词进行 inpainting 处理90%的时间都能获得满意的效果。

什么是自定义模型?
由Stability AI及其伙伴发布的官方模型称为基本模型。其中一些基本模型的示例包括 Stable Diffusion 1.4、1.5、2.0和2.1。
自定义模型是基于基本模型训练的。目前,大多数模型都是从v1.4或v1.5训练得出的。它们使用额外的数据来生成特定风格或对象的图像。
自定义模型的潜力是无限的,可以是动漫风格、迪士尼风格、另一个AI的风格等等。您尽可发挥自己的想象力。
下面列出了5种不同模型的比较结果。

我应该使用哪种模型呢?
如果您是新手的话,最好先使用基础模型。它们非常易学,且玩起来可以让你忙碌数月。
基础模型主要分为 v1 和 v2 两组。v1 模型包括 1.4 和 1.5。v2 模型则包括 2.0 和 2.1。
您可能认为应该从较新的 v2 模型入手。但是仍有人在努力弄清如何使用 v2 模型。与 v1 相比,v2 的图像效果并不一定更好。
我建议,如果您是 Stable Diffusion 的新手,应该使用 v1.5 模型。
如何训练一个新模型?
使用 Stable Diffusion 的一个优点是您可以完全掌控模型。如果您希望,您可以创建具有独特风格的自己的模型。训练模型的两种主要方法:(1)Dreambooth和(2)嵌入。
Dreambooth被认为更强大,因为它可以微调整个模型的权重。嵌入则不会修改模型,但会找到描述新主题或风格的关键字。
否定提示语(Negative prompts)
在提示语(Prompts)中,你会把你想要看到的内容放进去。而在否定提示语(Negative Prompts)中,你会把你不想看到的内容放进去。并非所有的 Stable Diffusion 服务都支持否定提示语,但这对于v1模型非常有价值,对于v2模型则是必须的。对于初学者来说,使用普适性的否定提示语也是可以的。了解更多关于否定提示语的信息:
否定提示语是如何工作的?
如何使用否定提示语?
如何使用Stable Diffusion制作大型印刷品?
Stable Diffusion的本地分辨率是v1模型的512×512像素。您不应该生成与512像素相差太远的宽度和高度的图像。请使用以下大小设置生成初始图像。
横向图像:将高度设置为512像素。将宽度设置得更高,例如768像素(2:3的宽高比)
纵向图像:将宽度设置为512像素。将高度设置得更高,例如768像素(3:2的宽高比)
如果您将初始宽度和高度设置得太高,您将会看到重复的主题。
下一步是将图像进行缩放。免费的AUTOMATIC1111 GUI带有一些流行的AI缩放器。
如何控制图像构图?
Stable Diffusion 技术正在迅速改进,有几种方法可以控制图像构图。
图生图(img2img)
您可以在生成新图像时要求Stable Diffusion粗略地按照输入图像的方向进行。这被称为图像对图像。下面是一个例子,使用一张鹰的输入图像生成一条龙,输出图像的构图沿用了输入图像。


ControlNet
ControlNet 同样利用一个输入图像来指导输出。但是它可以提取特定的信息,例如人类的姿势。下面是一个例子,使用 ControlNet 从输入图像中复制一个人的姿势。


区域提示
您可以使用称为区域提示器的扩展来指定某些图像部分的提示。这个技巧非常有助于仅在图像的某些部分绘制对象。
以下是一个示例:将狼放在左下角,将头骨放在右下角。

更多教程,请点击。
Depth-to-image
“Depth-to-image”是通过输入图片来控制构图的另一种方式。它可以检测输入图片的前景和背景。输出图像将遵循相同的前景和背景。下面是一个例子。


生成特定对象
真实人物
使用Stable Diffusion技术可以生成具有照片风格的逼真人物。以下是一些样例。
这需要使用正确的提示和特殊模型进行训练,以产生具有照片风格的真实人物。详细了解如何生成逼真人物的教程。




动物
动物也是Stable Diffusion用户中非常受欢迎的主题之一。
以下是一些样例。



阅读有关生成动物的教程以学习如何操作。
你可以用稳定扩散功能制作视频吗?
可以!Deforum是一种流行的制作带有 Stable Diffusion 效果的视频的方法,你可能已经在社交媒体上看到过一些。
它的效果就像这样。
阅读Deforum教程以学习如何制作这种视频。